2024 年如何绕过 Cloudflare

转自 ScrapeOps 官网的《How To Bypass Cloudflare in 2024》的机翻
据估计,有 40% 的网站使用Cloudflares内容分发网络 (CDN),对于希望抓取互联网上一些最受欢迎网站的开发人员来说,绕过 Cloudflare 的反机器人保护系统已成为一项重要要求。
幸运的是,我们可以绕过 Cloudflares 反机器人保护。然而,这并不是一件容易的事。
您可以采取多种方法来绕过 Cloudflare,每种方法都有各自的优点和缺点。
它们的范围从简单的(例如使用现成的工具)到极其复杂的(例如 Cloudflare 如何检测和阻止抓取工具的完全逆向工程)。
因此,在本指南中,我们将逐一介绍这些选项,以便您可以选择最适合您的选项。
-
向源服务器发送请求
-
抓取 Google 缓存版本
-
Cloudflare 求解器
-
使用强化的无头浏览器进行抓取
-
具有 Cloudflare 内置旁路的智能代理
-
逆向工程 Cloudflare 反机器人保护

一、向原始服务器
这并不总是可行,但绕过 Cloudflare 的最简单方法之一是将请求直接发送到网站源服务器 IP 地址,而不是发送到 Cloudflare 的 CDN 网络。
在这里,您不必欺骗 Cloudflare 认为您的请求来自真实用户,而是通过查找托管网站的原始服务器的 IP 地址并将您的请求发送到该服务器来完全绕过 Cloudflare。
完全绕过 Cloudflare 及其所有保护!

Cloudflare 是一个复杂的反机器人保护系统,但它是由以下人员设置的:
- 可能不完全理解 Cloudflare,
- 可能会偷工减料,或者
- 在 Cloudflare 上设置网站时会犯错误。
因此,有时稍微窥探一下,您就可以找到托管网站主版本的服务器的 IP 地址。
找到此 IP 地址后,您可以将抓取工具配置为将请求发送到此服务器,而不是已启用反机器人保护的 Cloudflares 服务器。
例如,受 Cloudflare 保护的站点PetsAtHome.com的原始 IP 地址可公开访问:
Origin IP Address --> 'http://88.211.26.45/'
有时,通过将源 IP 地址插入浏览器地址栏中来访问网站将不起作用,因为服务器可能需要 HTTP 标头HOST。在这种情况下,您可以使用curl或Postman等工具查询源服务器,它允许您设置HOST标头或向主机文件添加静态映射。
查找源服务器
有多种方法可以查找网站服务器的原始 IP 地址。以下是最常用的 3 种方法:
方法 1:SSL证书
如果目标网站使用 SSL 证书(大多数网站都是如此),那么这些 SSL 证书将在 Censys 数据库中注册。
尽管网站已将其网站部署到 Cloudflare CDN,但有时其当前或旧的 SSL 证书会注册到原始服务器。
您可以在 Censys 数据库中查找该网站,看看这些服务器中是否有任何服务器托管原始网站。
方法2:其他服务
有时,其他子域、邮件交换器 (MX) 服务器、FTP/SCP 服务或主机名托管在与主网站相同的服务器上,但不受 Cloudflare 网络的保护。
在这里您可以使用 Censys 数据库或 Shodan 检查其他子域的 DNS 记录或 A、AAAA、CNAME 和 MX DNS 记录,以缓解主服务器的 IP 地址。
如果该网站没有使用第三部分电子邮件提供商,一个技巧是将电子邮件发送到目标网站上不存在的电子邮件地址,并且假设发送失败,您应该收到来自电子邮件服务器的通知,其中[email protected]包含IP 地址。
方法 3:旧 DNS记录
每个服务器的 DNS 历史记录都可以在互联网上获取,因此有时网站仍托管在将其部署到 Cloudflare CDN 之前的同一台服务器上。因此,您可以使用 CrimeFlare等工具来查找它。
CrimeFlare 维护 Cloudflare 上托管的网站的可能源服务器数据库,该数据库源自当前和旧的 DNS 记录。
以下是一些可帮助您查找服务器原始 IP 地址的最佳工具:
有时,即使您找到网站服务器的实际 IP 地址,也无法访问它,例如当网站管理员正确限制服务器仅响应 Cloudflare IP 范围、将任何请求重定向到 Cloudflare CDN 时,或者如果 Origin CA使用证书
登台和开发服务器
如果找到看起来像原始服务器的东西,它实际上可能是真实网站的开发或临时服务器。虽然你永远不能 100% 确定你找到的服务器是原始服务器,但如果你可以浏览一下,数据看起来与 Cloudflare 受保护站点相同,可以在“原始版本”上注册帐户并登录真实的服务器有了它的网站,那么就应该可以将该网站视为真正的网站。
有关查找源服务器 IP 地址的更多信息,请查看这些指南:
如果完成上述操作后您仍找不到源服务器的 IP 地址,请不要担心。还有很多其他方法可以绕过 Cloudflare 保护。

二、抓取 Google 缓存版本
根据数据需要的新鲜程度,另一种选择是从 Google 缓存而不是实际网站中抓取数据。
当 Google 抓取网络以索引网页时,它会为其找到的数据创建缓存。大多数受 Cloudflare 保护的网站都允许 Google 抓取其网站,因此您可以刮取此缓存。
抓取 Google 缓存可能比抓取 Cloudflare 保护的网站更容易,但只有当您要抓取的网站上的数据不经常更改时,这才是一个可行的选择。
要抓取 Google 缓存,只需添加https://webcache.googleusercontent.com/search?q=cache:到您要抓取的 URL 的开头即可。
例如,如果您想抓取https://www.petsathome.com/shop/en/pets/dog,那么抓取 Google 缓存版本的 URL 将为:
'https://webcache.googleusercontent.com/search?q=cache:https://www.petsathome.com/shop/en/pets/dog'
未缓存的网站
某些网站(例如 LinkedIn)告诉 Google 不要缓存其网页,或者 Google 的抓取频率太低,这意味着某些页面可能尚未缓存。所以这个方法并不适用于每个网站。

三、Cloudflare求解器
好吧,如果您找不到源服务器并且无法使用 Google 缓存,那么我们需要直接绕过 Cloudflare。
绕过 Cloudflare 的一种方法是使用多种 Cloudflare 求解器之一来解决 Cloudflare 挑战:
已经开发了许多 Cloudflare 求解器:
- cloudscraper Guide here
- cloudflare-scrape
- CloudflareSolverRe
- Cloudflare-IUAM-Solver
- cloudflare-bypass [Archived]
- CloudflareSolverRe
然而,它们经常会因 Cloudflare 更新而过时并停止工作。
目前,性能最好的 Cloudflare 求解器是 FlareSolverr。
FlareSolverr
FlareSolverr 是一个代理服务器,可用于绕过 Cloudflare 和 DDoS-GUARD 保护。
运行时,FlareSolverr会启动一个代理服务器,该服务器使用puppeteer和Stealth Plugin将您的请求转发到 Cloudflare 受保护的网站,并等待 Cloudflare 挑战解决(或超时),然后将响应和 Cookie 返回到您的抓取工具。
从这里,您可以使用这些 cookie 使用普通的 HTTP 客户端绕过 Cloudflare。
与针对每个请求使用强化的无头浏览器相比,这种方法的优点在于,您只需要使用 FlareSolverr 检索有效的 Cloudflare cookie,然后可以使用资源密集程度低得多的 HTTP 客户端(例如 Python 请求、HTTPX、Node Axios 等)继续进行抓取.)。
您可以使用 Docker(已包含 Firefox 浏览器)在服务器上安装 FlareSolverr,因此设置非常简单。
docker run -d \
--name=flaresolverr \
-p 8191:8191 \
-e LOG_LEVEL=info \
--restart unless-stopped \
ghcr.io/flaresolverr/flaresolverr:latest
运行时,FlareSolverr会启动一个服务器,该服务器使用 Python Selenium和未检测到的 chromedriver,通过模拟真实的 Web 浏览器来解决 Cloudflares Javascript 和浏览器指纹识别挑战。
FlareSolverr 使用 Selenium 浏览器打开目标 URL,并等待 Cloudflare 挑战得到解决,然后将 HTML 和 cookies Cloudflare 返回到浏览器。
由于 FlareSolverr在幕后使用 Selenium未检测到的 chromedriver来绕过 Cloudflare,因此在某些情况下也可用于绕过 DataDome(可能需要修改)。
要使用 FlareSolverr,您需要配置抓取器以将要抓取的 URL 发送到 FlareSolverr 服务器:
import requests
post_body = {
"cmd": "request.get",
"url":"https://cloudflare.com/",
"maxTimeout": 60000
}
response = requests.post('http://localhost:8191/v1', headers={'Content-Type': 'application/json'}, json=post_body)
print(response.json())
然后它将使用 cookie 和 HTML 响应进行响应:
{
"status": "ok",
"message": "Challenge not detected!",
"solution": {
"url": "https://cloudflare.com/",
"status": 200,
"cookies": [
{
"domain": ".cloudflare.com",
"expiry": 1705160731,
"httpOnly": false,
"name": "datadome",
"path": "/",
"sameSite": "Lax",
"secure": true,
"value": "5H6S1eVa4qoqPbzbQxo4fGjFNdeY7ZUE40Qlk0ZQTiLk5b8aqv4nYNE6-JC1MQtUs4k4lBXf-ScmiijLOk1QlolRRVVlUTtc1i_maPBzFSz4AJVtM~_iWqJGNPZpbJge"
}
...
],
"userAgent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"headers": {},
"response": "<html><head>...</head><body>...</body></html>"
},
"startTimestamp": 1673459546891,
"endTimestamp": 1673459560345,
"version": "3.0.2"
}
使用 FlareSolverr 绕过 Cloudflare 并不可靠,因为它无法检测 Cloudflare 挑战和禁令,因此您需要自己验证响应。
内存问题
由于无头浏览器可能会消耗大量内存,并且对 FlareSolverr 的每个请求都会启动一个新的浏览器窗口,因此如果您向 FlareSolverr 发送许多请求并且您的计算机没有足够的 RAM,FlareSolverr 可能会导致您的服务器崩溃。因此,您需要限制发送的请求数量和/或将其部署在更大的服务器上。
有时,CloudFlare 不仅提供数学计算和需要解决的 Javascript 浏览器测试,有时还要求用户解决验证码。尽管 FlareSolverr 确实支持通过第三方验证码求解器进行验证码求解,但目前,没有任何自动化验证码求解解决方案能够像 Cloudflare 使用 hCAPTCHA 那样工作。

四、使用强化的无头浏览器
另一种选择是使用无头浏览器完成整个抓取工作,该浏览器经过强化,看起来像真正的用户浏览器。
Vanilla 无头浏览器会在 JS 指纹中泄露其身份,反机器人系统可以轻松检测到。然而,开发人员已经发布了许多强化的无头浏览器来修补最大的漏洞:
- Puppeteer:puppeteer的隐形插件。
- Playwright: Playwright 即将推出隐形插件。关注这里和这里的事态发展。
- Selenium:未检测到的 chromedriver是一个优化的 Selenium Chromedriver 补丁。
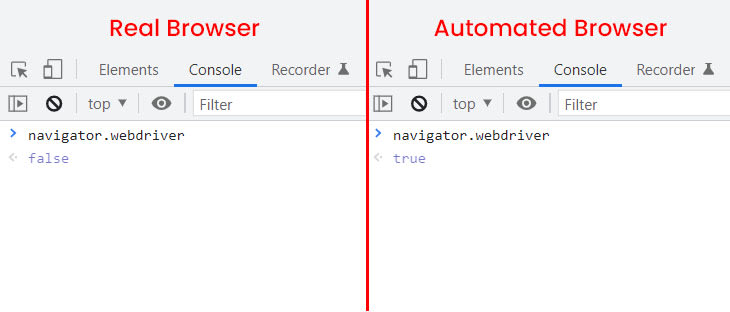
例如,Puppeteer、Playwright 和 Selenium 等无头浏览器中存在的众所周知的泄漏是navigator.webdriver. 在普通浏览器中,该值设置为false,但是,在未经强化的无头浏览器中,它设置为true。
这些隐形插件试图修补 200 多个已知的无头浏览器漏洞。然而,由于浏览器不断变化,人们相信这个数字要高得多,并且不透露他们所知道的所有泄漏符合浏览器开发人员和反机器人公司的利益。
无头浏览器隐形插件修补了大部分浏览器漏洞,并且通常可以绕过许多反机器人服务,例如Cloudflare、PerimeterX、Incapsula、DataDome,具体取决于它们在网站上实施的安全级别。
然而,他们并没有得到全部。要真正使您的无头浏览器看起来像真正的浏览器,那么您必须自己完成此操作。
让无头浏览器更不易被检测到的另一种方法是将它们与高质量的住宅或移动代理配对。这些代理通常比数据中心代理具有更高的 IP 地址信誉评分,并且反机器人服务更不愿意阻止它们,从而使它们更加可靠。
将无头浏览器与住宅/移动代理配对的缺点是成本会快速增加。
由于住宅和移动代理通常按使用的 GB 带宽收费,并且使用无头浏览器呈现的页面平均可消耗 2MB(而没有无头浏览器则为 250kb)。这意味着随着规模的扩大,它可能会变得非常昂贵。
以下是使用来自BrightData的住宅代理和无头浏览器的示例,假设每页 2MB。
| 页数 | 带宽 | 每 GB 成本 | 总成本 |
|---|---|---|---|
| 25,000 | 50GB | 13 美元 | $625 |
| 100,000 | 200GB | 10 美元 | 2000 美元 |
| 百万 | 2TB | 8 美元 | 16,000 美元 |
寻找廉价的住宅和移动代理:
如果您想比较代理提供商,您可以使用这个免费的代理比较工具,它可以比较住宅代理计划和移动代理计划。
示例:Selenium 未检测到的 ChromeDriver
例如,以下是如何使用 Selenium 的unDetected-chromedriver来抓取受 Cloudflare 保护的网站。
首先,您只需通过 pip安装unDetected-chromedriver包:
pip install undetected-chromedriver
现在安装了**未检测到的 chromedriver,**我们可以设置我们的 scraper/bot 来使用它而不是默认的 Chromedriver。
import undetected_chromedriver as uc
driver = uc.Chrome()
driver.get('https://cloudflare.com/')
为了启用经过身份验证的代理,在下面的示例中,我们将从unDetected-chromedriverundetected_chromedriver包加载seleniumwire而不是直接从unDetected-chromedriver 包加载,并将代理设置传递到Chromedriver 的属性中。seleniumwire_options
import seleniumwire.undetected_chromedriver as uc
## Chrome Options
chrome_options = uc.ChromeOptions()
## Proxy Options
proxy_options = {
'proxy': {
'http': 'http://user:pass@ip:port',
'https': 'https://user:pass@ip:port',
'no_proxy': 'localhost,127.0.0.1'
}
}
## Create Chrome Driver
driver = uc.Chrome(
options=chrome_options,
seleniumwire_options=proxy_options
)
driver.get('https://cloudflare.com/')
标准Selenium ChromeDriver泄露了大量信息,反机器人系统可以使用这些信息来确定它是自动浏览器/抓取工具还是访问网站的真实用户。
Selenium UnDetected ChromeDriver通过修补反机器人系统用于检测 Selenium bot/scraper 的绝大多数方式来增强标准 Selenium ChromeDriver。
使 DataDome、Imperva、Perimeterx、Botprotect.io 和 Cloudflare 等反机器人系统更难检测和阻止您的 Selenium 机器人/抓取工具。
有关如何使用 Selenium UnDetected ChromeDriver 的更多信息,请在此处查看我们的指南。

五、具有 Cloudflare 内置旁路的智能代理
使用开源 Cloudflare 求解器和预强化无头浏览器的缺点是,像 Cloudflare 这样的反机器人公司可以看到他们如何绕过他们的反机器人保护系统并轻松修补他们利用的问题。
因此,大多数开源 Cloudflare 绕过在停止工作之前只有几个月的保质期。
使用开源 Cloudflare 旁路的替代方案是使用智能代理来开发和维护自己的私有 Cloudflare 旁路。
这些通常更可靠,因为 Cloudflare 更难为它们开发补丁,而且它们是由代理公司开发的,这些公司有经济动机保持领先 Cloudflare 1 步,并在它们停止工作的那一刻修复它们的旁路。
大多数智能代理提供商(ScraperAPI、Scrapingbee、Oxylabs、Smartproxy)都有某种形式的 Cloudflare 绕过,这些绕过在不同程度上起作用,成本也各不相同。
但是,最好的选择之一是使用 ScrapeOps 代理聚合器,因为它将 20 多个代理提供商集成到同一个代理 API 中,并为您的目标域找到最佳/最便宜的代理提供商。
您只需将 API 请求添加到即可激活 ScrapeOps 的 Cloudflare Bypass,ScrapeOps 代理将使用适用于您的目标域的最佳和最便宜的 Cloudflare 绕过。bypass=cloudflare_level_1
import requests
response = requests.get(
url='https://proxy.scrapeops.io/v1/',
params={
'api_key': 'YOUR_API_KEY',
'url': 'http://example.com/', ## Cloudflare protected website
'bypass': 'cloudflare_level_1',
},
)
print('Body: ', response.content)
提示:
Cloudflare 是当今网站最常用的反机器人系统,绕过它取决于网站启用了哪些安全设置。
为了解决这个问题,我们提供了 3 种不同的 Cloudflare 绕过方法,旨在解决每个安全级别的 Cloudflare 挑战。
| 安全级别 | 旁路 | API 积分 | 描述 |
|---|---|---|---|
| 低 | cloudflare_level_1 |
10 | 用于绕过启用低安全设置的受 Cloudflare 保护的站点。 |
| 中等 | cloudflare_level_2 |
35 | 用于绕过启用了中等安全设置的受 Cloudflare 保护的站点。在大型计划中,信用倍数将增加,以保持每千个请求 3.50 美元的统一费率。 |
| 高 | cloudflare_level_3 |
50 | 用于绕过启用了高安全设置的受 Cloudflare 保护的站点。在大型计划中,信用倍数将增加,以保持每千个请求 4 美元的统一费率。 |
您可以在此处注册,获得具有 1,000 个免费 API 积分的 ScrapeOps API 密钥。
采用这种方法的好处是,您可以使用普通的 HTTP 客户端,而不必担心:
- 查找源服务器
- 强化无头浏览器
- 管理大量无头浏览器实例并处理内存问题
- 对 Cloudflare 反机器人保护进行逆向工程
因为这一切都在 ScrapeOps 代理聚合器中管理

六、逆向工程 Cloudflare 反机器人保护
绕过 Cloudflare 反机器人保护的最后也是最复杂的方法是对 Cloudflare 的反机器人保护系统进行实际逆向工程,并开发一种绕过所有 Cloudflare 反机器人检查的方法,而无需使用完全强化的无头浏览器实例。
这种方法有效(并且是许多智能代理解决方案所做的),但是,它不适合胆小的人。
**优点:**这种方法的优点是,如果您进行大规模抓取,并且不想运行数百个(如果不是数千个)昂贵的完整无头浏览器实例。相反,您可以开发资源效率最高的 Cloudflare 旁路。一款专门为通过 Cloudflare JS、TLS 和 IP 指纹测试而设计的。
**缺点:**这种方法的缺点是,您必须深入研究故意使其难以从外部理解的反机器人系统,并分别测试不同的技术来欺骗他们的验证系统。然后在 Cloudflare 继续开发其反机器人保护时维护此系统。
可以这样做,但我只会建议某人采取这种方法,除非他们是:
- 真正对逆向工程复杂的反机器人系统的智力挑战感兴趣,或者
- 拥有更具成本效益的 Cloudflare 旁路所带来的经济回报,保证了您必须投入数天或数周的工程时间来构建和维护它。
对于抓取量非常大(每月超过 5 亿页)的公司或业务依赖经济高效的方式访问站点的智能代理解决方案的公司来说,构建您自己的自定义 Cloudflare 旁路可能是一个不错的选择。
对于大多数其他开发人员来说,您最好使用其他五种 Cloudflare 绕过方法之一。
对于那些确实想要尝试的人,以下是 Cloudflare 的Web 应用程序防火墙 (WAF)的工作原理以及如何绕过它的详细介绍。
了解 Cloudflare 的机器人管理器
当我们说我们想要绕过 Cloudflare 时,我们真正的意思是我们想要绕过他们的Bot Manager ,该管理器是他们的Web 应用程序防火墙 (WAF)的一部分。
旨在减轻恶意机器人攻击而不影响真实用户的系统。
Cloudflares 机器人检测系统可分为两类:
- **后端检测技术:**这些是在后端服务器上执行的机器人指纹识别技术。
- **客户端检测技术:**这些是在用户浏览器(客户端)中执行的机器人指纹识别技术。
要绕过 Cloudflare,您必须通过两组验证测试。
通过 Cloudflare 的后端检测技术
以下是 Cloudflare 在服务器端执行的已知后端机器人指纹识别技术以及如何传递它们:
代理质量
Cloudflare 进行的最基本测试之一是计算您用于发送请求的 IP 地址的 IP 地址信誉评分。考虑到它是否属于任何已知机器人网络的一部分、其位置、ISP、声誉历史等因素。
要获得最高的 IP 地址信誉分数,您应该使用住宅/移动代理而不是数据中心代理或与 VPN 关联的任何代理。但是,如果数据中心代理质量很高,那么它们仍然可以工作。
HTTP 浏览器标头
Cloudflare 还会分析您随请求发送的 HTTP 标头,并将它们与已知浏览器标头模式的数据库进行比较。
大多数 HTTP 客户端默认发送用户代理和其他明确标识它们的标头,因此您需要覆盖这些标头并使用与您想要显示的浏览器类型相匹配的完整浏览器标头集。在本标头优化指南中,我们详细介绍了如何执行此操作,您可以使用我们的免费假浏览器标头 API来生成假浏览器标头列表。
TLS 和 HTTP/2 指纹
Cloudflare 使用的更复杂的指纹检测系统是 TLS 和 HTTP/2 指纹识别。每个 HTTP 请求客户端都会生成一个静态 TLS 和 HTTP/2 指纹,Cloudflare 可以使用它们来确定请求是来自真实用户还是机器人。
不同版本的浏览器和 HTTP 客户端往往具有不同的 TLS 和 HTTP/2 指纹,然后 Cloudflare 可以将这些指纹与您发送的浏览器标头进行比较,以确保您确实是您所设置的浏览器标头中声称存在的人。
问题在于,伪造 TLS 和 HTTP/2 指纹比简单地向请求中添加伪造的浏览器标头要困难得多。您首先需要捕获并分析来自要模拟的浏览器的数据包,然后更改用于发出请求的 TLS 和 HTTP/2 指纹。
但是,许多 HTTP 客户端(例如Python Requests)无法让您更改这些 TLS 和 HTTP/2 指纹。您将需要使用编程语言和 HTTP 客户端,例如Golang HTTP或Got,它为您提供了对请求的足够低级控制,以便您可以伪造 TLS 和 HTTP/2 指纹。
像CycleTLS、Got Scraping这样的库。utls帮助您在 GO 和 Javascript 中欺骗 TLS/JA3 指纹。
这是一个复杂的主题,因此我建议您深入了解 TLS 和 HTTP/2 指纹识别的工作原理。以下是一些可以帮助您的资源:
**重要提示:**匹配浏览器标头、TLS 和 HTTP/2 指纹
Cloudflare 使用这些指纹识别方法检测您的抓取工具的方式是,当您使用用户代理和浏览器标头发出请求时,表明您是 Chrome 浏览器,但是,您的 TLS 和 HTTP/2 指纹表明您正在使用 Python 请求 HTTP 客户端。
因此,要欺骗 Cloudflares 指纹测试,您需要确保浏览器标头、TLS 和 HTTP/2 指纹全部一致,并告诉 Cloudflare 请求来自真实的浏览器。
当您使用自动浏览器发出请求时,所有这些都会为您处理。然而,当您尝试使用普通 HTTP 客户端发出请求时,事情会变得相当棘手。
Cloudflare 的服务器端检测技术是其第一道防线。如果您未通过这些测试中的任何一项,您的请求将受到 Cloudflare 的质疑或阻止。
服务器端检测技术会为您的请求分配一个风险评分,然后 Cloudflare 使用该评分来确定在客户端向您显示哪些挑战(如果有)。
每个网站都可以设置自己的反机器人保护风险阈值,以确定应该挑战谁以及挑战什么(后台客户端挑战或验证码)。因此,您的目标是获得尽可能最低的风险评分。特别是对于最受保护的网站。
通过 Cloudflare 的客户端检测技术
好的,假设您已经能够构建一个系统来通过所有 Cloudflares 服务器端反机器人检查,现在您需要处理其客户端验证测试。
当 Cloudflare 在允许您访问网站之前向您显示其安全页面时,会发生这些客户端验证测试。这是一个例子。
当您(或您的抓取工具)首次访问网站时,Cloudflare 将显示此页面,并且您的浏览器在后台解决各种挑战,以向 Cloudflare 证明您不是机器人。
如果您被标记为机器人,那么您将收到403 Access Denied / Forbidden 错误。
您的请求在服务器端测试期间获得的风险评分可能会影响它运行的客户端验证测试。最重要的是,它是否需要您解决 CAPTHCA。
有三种通用方法可以解决您在此页面等待时出现的客户端反机器人挑战:
- **使用自动化浏览器:**前面提到过,如果您使用强化的浏览器打开页面,那么它将承担解决 Cloudflare JavaScript 挑战的大量繁重工作。
- 在沙箱中模拟浏览器:您可以使用JSDOM等库在沙箱中模拟浏览器,这会减少资源占用,并让您更好地控制您希望它呈现的内容。
- **构建挑战求解器算法:**构建无需浏览器即可通过检查的算法。这是最难的方法,因为您需要完全理解 Cloudflares 客户端检查、对 Javascript 挑战脚本进行反混淆,然后创建算法来解决它们。
以下是 Cloudflare 在用户浏览器中执行的主要客户端机器人指纹识别技术,您需要通过这些技术:
浏览器 Web API
现代浏览器有数百个 API,允许我们作为开发人员设计与用户浏览器交互的应用程序。不幸的是,当 Cloudflare 在用户浏览器中加载时,它也可以访问所有这些 API。
允许它访问有关浏览器环境的大量信息,然后可以使用这些信息来检测撒谎其真实身份的爬虫。例如Cloudflare可以查询:
- **特定于浏览器的 API:**某些 Web API
window.chrome仅存在于 Chrome 浏览器上。因此,如果您的浏览器标头、TLS 和 HTTP/2 指纹都表明您正在使用 Chrome 浏览器发出请求,但当window.chromeCloudflare 检查浏览器时 API 不存在,那么这显然表明您正在伪造指纹。 - 自动化浏览器 API:Selenium等自动化浏览器具有
window.document.__selenium_unwrapped. 如果 Cloudflare 发现这些 API 存在,那么它就知道您不是真正的用户。 - 沙盒浏览器模拟器 API:像JSDOM这样的沙盒浏览器浏览器模拟器,运行在 NodeJs 中,具有
process仅存在于 NodeJs 中的对象。 - **环境 API:**如果您的用户代理表示您正在使用 MacO 或 Windows 计算机,但该
navigator.platform值设置为Linux x86_64,那么这会使您的请求看起来可疑。
如果您使用的是强化浏览器,它将修复很多此类漏洞,但是,您可能需要修复更多漏洞,并确保您的浏览器标头以及 TLS 和 HTTP/2 指纹与从浏览器 Web API 返回的值相匹配。
画布指纹识别
Cloudflare 用于检测抓取工具的另一种技术是画布指纹识别,该技术允许 Cloudflare 对所使用的设备类型(浏览器、操作系统和系统图形硬件的组合)进行分类。
Cloudflare 使用Google 的毕加索指纹识别。生成画布指纹。
Canvas 指纹识别是最常见的浏览器指纹识别技术之一,它使用 HTML5 API 通过 Javascript 绘制页面的图形和动画,然后可用于生成设备的指纹。
检查您的画布指纹
您可以使用BrowserLeaks Live Demo查看浏览器画布指纹。
Cloudflare 维护着大量合法画布指纹和用户代理对的数据集。因此,当请求来自一个在标头中声称是在 Windows 计算机上运行的 Firefox 浏览器的用户,但他们的画布指纹表明他们实际上是在 Linux 计算机上运行的 Chrome 浏览器时,这就是 Cloudflare 的标志:质疑或阻止请求。
事件跟踪
如果您需要浏览网页或与网页交互以获取所需的数据,那么您将不得不应对 Cloudflares 事件跟踪。
Cloudflare 向网页添加事件侦听器,以便它可以监视用户操作,例如鼠标移动、单击和按键。如果您有一个需要与页面交互的抓取工具,但鼠标从未移动,那么这对 Cloudflare 来说是一个明确的信号,表明该请求来自自动浏览器而不是真正的用户。
验证码
在抓取 Cloudflare 受保护的网站时,您将面临的最困难的 Cloudflare 反机器人挑战可能是解决其 CAPTCHA 挑战。

Cloudflare 仅在以下情况下向用户显示验证码挑战:
- Cloudflare 为该请求提供了高风险评分。
- 该网站已将其安全性配置为有时或始终显示验证码挑战。
幸运的是,大多数网站不愿意显示验证码挑战,因为众所周知它们会损害用户体验。
在极少数情况下,网站管理员已将 Cloudflare 配置为在每个请求上显示验证码,那么您将需要使用基于人工的验证码解决服务来解决他们的 hCaptcha 挑战,因为自动验证码解决程序无法解决 hCaptcha 验证码。这并不理想,因为它会使抓取变得非常缓慢且昂贵。
否则,您应该尽可能优化您的抓取工具,以降低 Cloudflare 分配给它们的风险评分。这样您应该能够避免完全处理它们。
低电平旁路
总的来说,实际上,为 Cloudflares 反机器人系统进行逆向工程和开发低级旁路(不使用无头浏览器)非常具有挑战性,因为您需要:
- 加载等候室页面时拦截 Cloudflare 网络请求
- 对 Cloudflare 代码进行反混淆
- 解密混淆代码中包含的 Javascript 挑战
- 了解反混淆代码中包含的 Javascript 挑战
- 解决 Javascript 挑战并返回正确的结果。
以下是 Cloudflare 执行的一些浏览器 API 测试的反混淆片段。
function _0x15ee4f(_0x4daef8) {
return {
/* .. */
wb: !(!_0x4daef8.navigator || !_0x4daef8.navigator.webdriver),
wp: !(!_0x4daef8.callPhantom && !_0x4daef8._phantom),
wn: !!_0x4daef8.__nightmare,
ch: !!_0x4daef8.chrome,
ws: !!(
_0x4daef8.document.__selenium_unwrapped ||
_0x4daef8.document.__webdriver_evaluate ||
_0x4daef8.document.__driver_evaluate
),
wd: !(!_0x4daef8.domAutomation && !_0x4daef8.domAutomationController),
};
}
我们将在另一篇文章中更详细地讨论如何实际逆向工程 Cloudflare 的 Javascript 挑战,因为这是一个大主题。
更多网页抓取指南
因此,当谈到绕过 Cloudflare 时,您有多种选择。有些非常快速和简单,有些则复杂得多。每个都有自己的权衡。
如果您想了解如何抓取一些热门网站,请查看我们的其他如何抓取指南:
或者,如果您想了解有关网页抓取的更多信息,请务必查看网页抓取手册,或查看我们更深入的指南之一: