适用于 Succinct Trie 的一种“路径压缩”的优化思路
目前实现的 Succinct Trie 结构,对于长字符串(UUID)场景查询性能较差,仅有 FSA 的一半。因此这次我将介绍一种自己琢磨出来的优化思路,关于 Succinct Trie 是如何实现“路径压缩”来加速搜索的。
p.s. 不了解 Succinct Trie 的话,可以去看这篇博客《一种基于 LOUDS 编码的压缩字典树》
现状分析
目前,Succinct Trie 基于 LOUDS 编码以 BFS 的顺序编码整棵树。对于查询一个字符串是否存在(正向搜索),每成功匹配一个字符后都需要调用 select1() 方法计算子节点位置才能向下层转移,而 select1() 方法是一个比较耗时的操作。如果要查询的平均字符串较长,那么查询单个字符串就会耗费更多的时间。这也是为什么在长字符串场景,它的性能会很差的原因。
Succinct Trie 本质上也是 Trie 树,参考普通 Trie 树的构造情况,只压缩前缀的话,对于那些重复率低的字符串,可能会形成大量的又深又长的单链,如下图的极端情况。对于目前的简洁树来说,这些单链既没法通过压缩相同字符来减少空间,又需要多次调用 select1() 方法来向下层转移匹配。比如输入“abcde”,就要调用 5 次select1() 方法来转移状态。如果用来存存储 UUID,不算连字符就有 32 个字符,耗费的时间会更多...
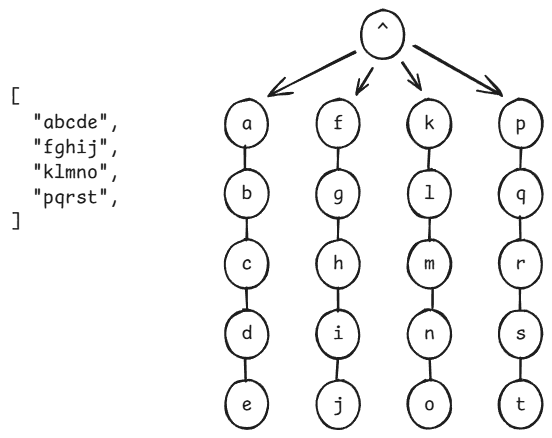
注:图中的字母应该放在其所在节点的扇入“边”上比较合适,这里为了好画放在节点内
优化思路
那么,普通的 Tire 树如何处理这种存在大量又深又长的单链的情况 —— 路径压缩。
这种方法通过将只有一个子节点的链状节点合并,使得一条边可以存储多个字符,从而减少树的深度和节点数量。这种方法详细各位已经耳熟能详了,不再赘述它的实现原理。
我们此处重点关注的不是它压缩了空间,而是关注它提升了查询性能。之所以能加速查询,根本上是减少了向下转移的次数,通过将节点压缩,使得一次转移就能将单链上的字符全部获取从而快速匹配。
那我们是否也能借鉴这种压缩节点的方法来减少转移次数呢?
直接给出我的结论:压缩节点不可照搬。因为普通 Tire 树的节点一般是以一个对象为单位,想要往一个节点对象里面多存点字符只需要将 char 类型的 value 字段改成 String 类型即可。但简洁 Trie 的节点是以数组元素为单位来节省对象头开销,是额外使用一个 char[] 数组来存字符,并通过计算获取对应下标。对于数组来说,每个元素的空间都固定,不可以往一个槽位里额外添加别的字符(如果你打算用 char[][],那样会引入数组对象的头部开销)
那么如何解决?不妨换个思路,我们不要关注如何压缩节点,而是关注一些本质的东西:如何在当前节点不调用 select1() 方法向下转移的情况下,获取该节点下方单链上的所有字符?
“节点压缩”通过将下方单链上的字符全都塞入当前节点中,来实现这个目的。那我们还能用什么办法来达到这个目的呢?
不卖关子了,这里给出我的一种思路:通过将下方的单链节点全部转换成当前节点的兄弟节点。从普通 Trie 树的角度来看很奇怪,但从以 BFS 遍历的方式将每层节点的字符存入 char[] 数组的 Succinct Trie 来说就太适合了,如下图所示。
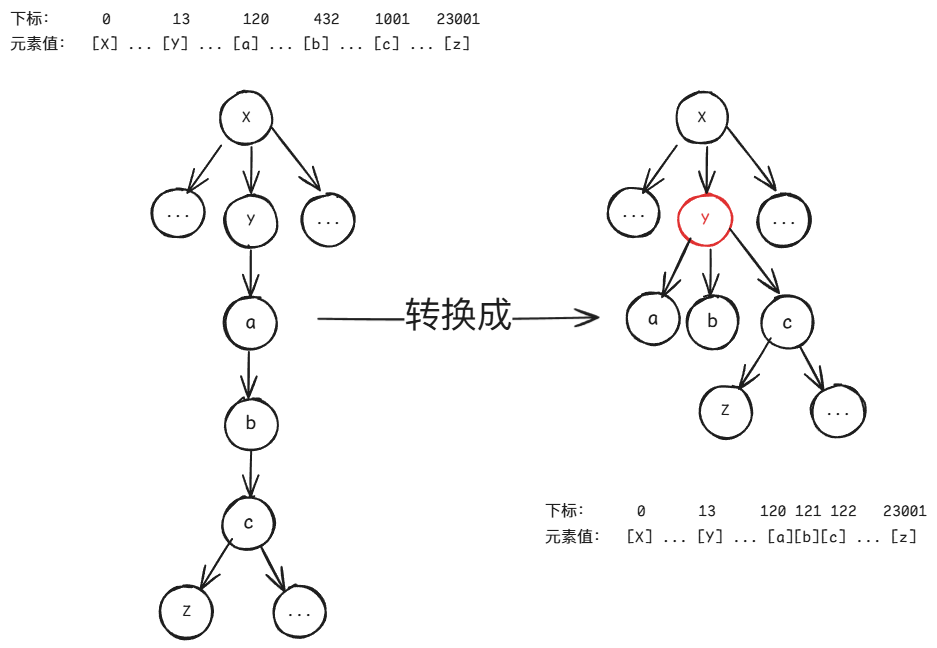
对于匹配 xyabcz 这个字符串
- 第一颗树的匹配流程是:从
X开始,向下转移 5 次完成匹配,期间需要调用 5 次select1()来计算出下一个字符所在的下标从而实现转移 - 第二颗树的匹配流程是:从
X开始,向下转移一次到Y,发现该节点为压缩节点,那么说明该节点的子节点是由原先一条单链转换成的。那么匹配这条单链只需要先向下转移到第一个a节点,然后基于a节点的下标不断自增就能获取原先单链上的所有字符,由于以 BFS 的顺序存储字符数组,因此兄弟节点字符的下标一定与当前节点在数组中相邻。至于如何判断是否将压缩节点的子节点都遍历完了,只需要检查当前节点是否有子节点即可。整个过程只需调用 3 次select1(),单链越长,省去的调用越多。
这个思路只适用于用 BFS 顺序额外数组存储字符的 Succinct Trie。因为需要额外付出小部分的空间来标记“压缩节点”,但实际上压缩的只有路径,也就是树高,节点本身的占用和总数都没变
总结
本篇文章旨在提供一个优化思路,具体的代码实现我已经实现验证过了,但由于引入了第三方依赖,没法直接将单文件放上来就能运行,所以这回就不放代码了。
给出一些简略的对比测试结果仅供参考,数据是随机生成的 100 万无序英文字符串:
- 长度 6 - 10 的短字符串:分词场景,查询性能提升 46%,存储空间增加 7%
- 长度 32 的长字符串:UUID 场景,查询性能提升 182%,存储空间增加 8%